经过嵌入,一句话里的token会对应向量,但是这个向量仅仅包含自身的词义,特别是多义词的情况下,有不同含义但是是同一个token对应的向量是一样的
以单头注意力机制single-headed attention与自注意力机制self-attention为例
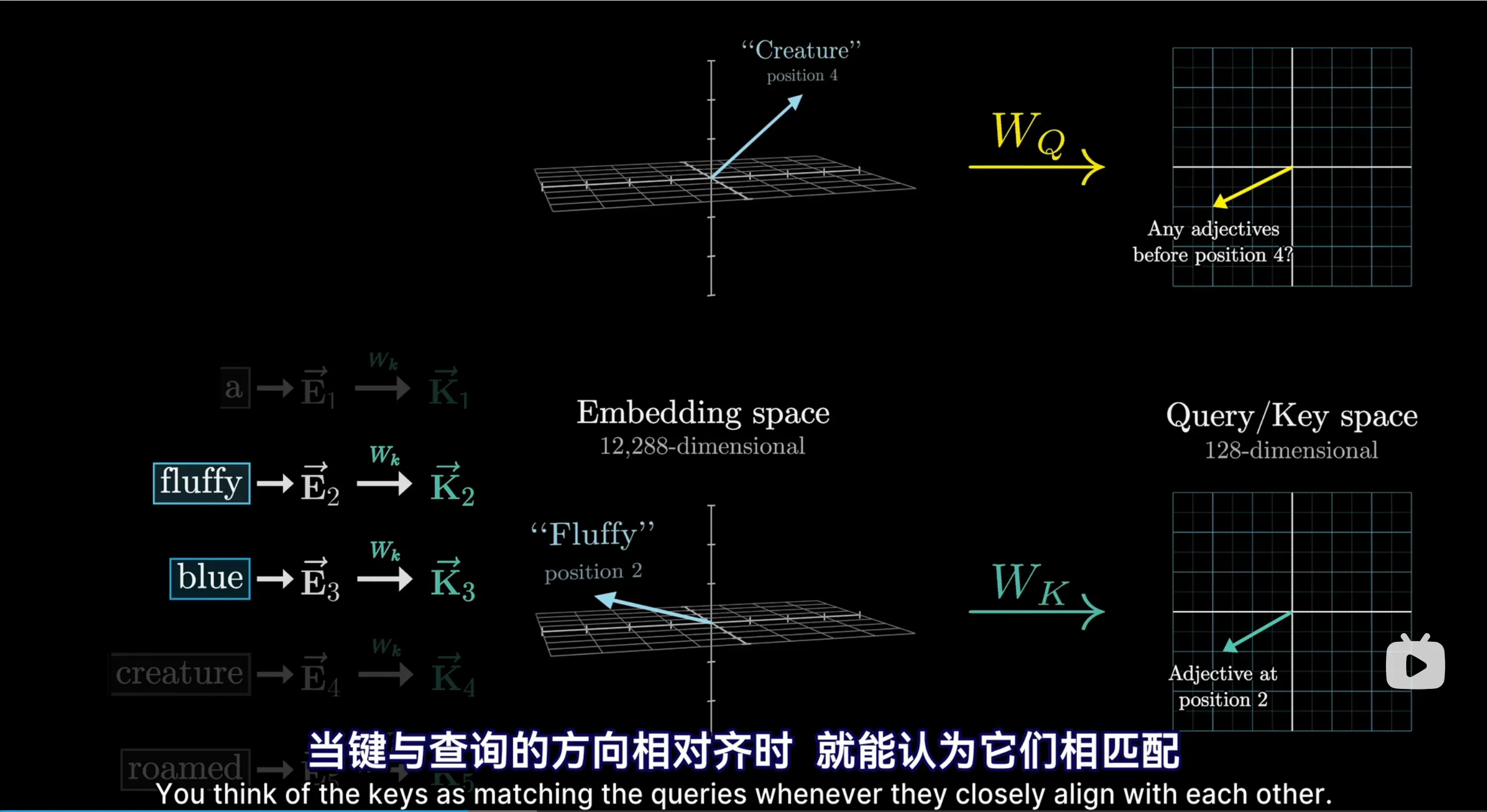
所有token会与一个\(W_Q\)查询query矩阵相乘,得到自己的query向量;也会与一个\(W_k\)键矩阵相乘,得到自己的key键。query和key向量的维数比token向量低很多,所以这个矩阵和线性变换其实是向低维空间的映射
然后将query和key两两做点积,得到的结果就是两者的匹配程度
视频里的例子是,对于creature这个词向量,产生的query可能是“我之前有没有形容词?”,然后这与fluffy和blue这两个词向量的key相匹配

得到不同词之间的相关性程度,这些计算出的点积之后要作为权重对token向量进行调整,所以要进行softmax以匹配权重的性质
softmax之后,这个网格矩阵被称作注意力模式 attention pattern,可以看出矩阵的大小取决于上下文长度context size的平方
接下来根据这些权重调整向量,每一个向量都会与一个\(W_V\)值矩阵相乘,得到value向量,根据刚刚的权重得到调整后的向量
这些value向量可以理解成“如果我要对别的向量做调整,那么调整的向量是什么”
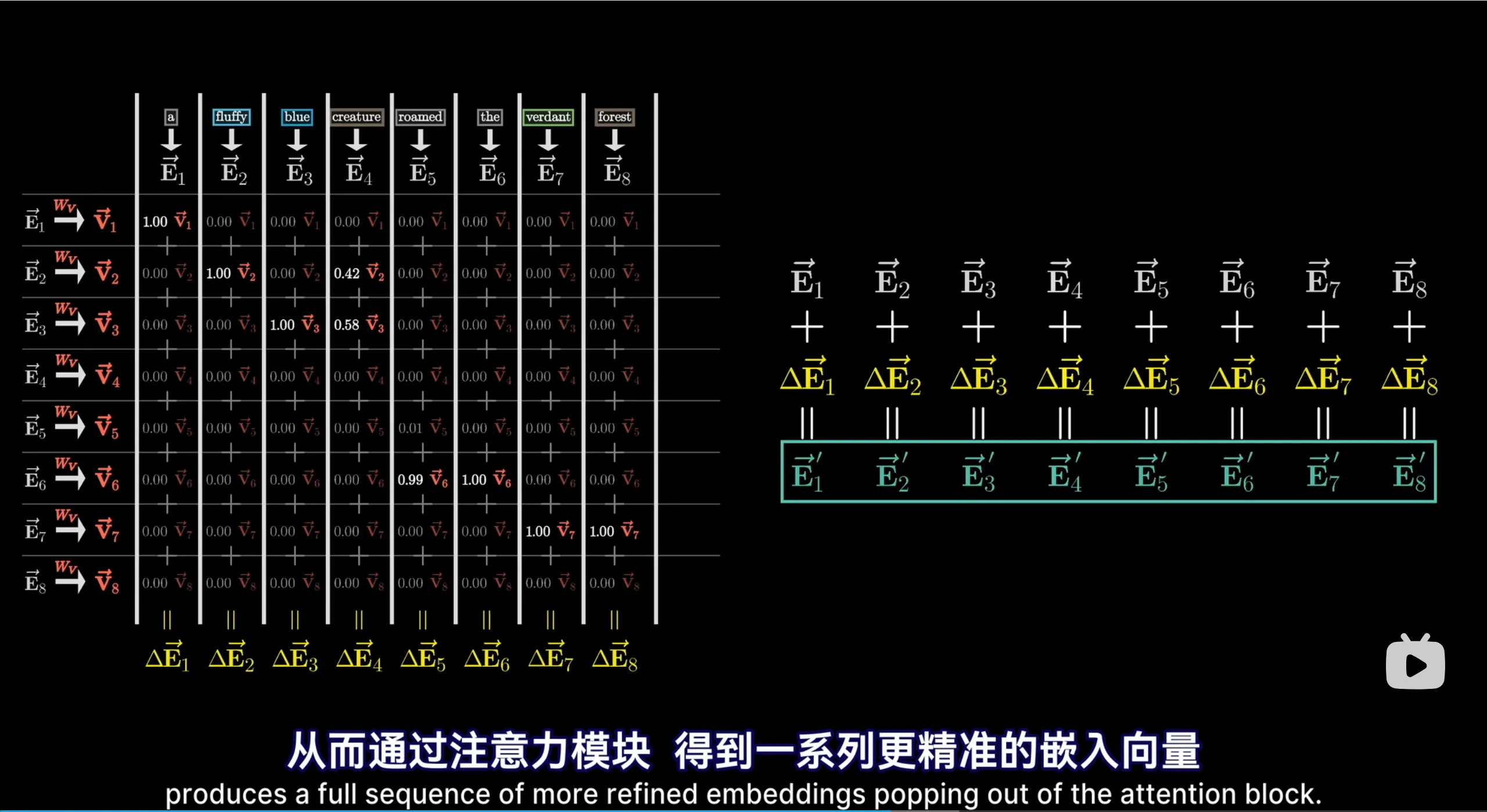
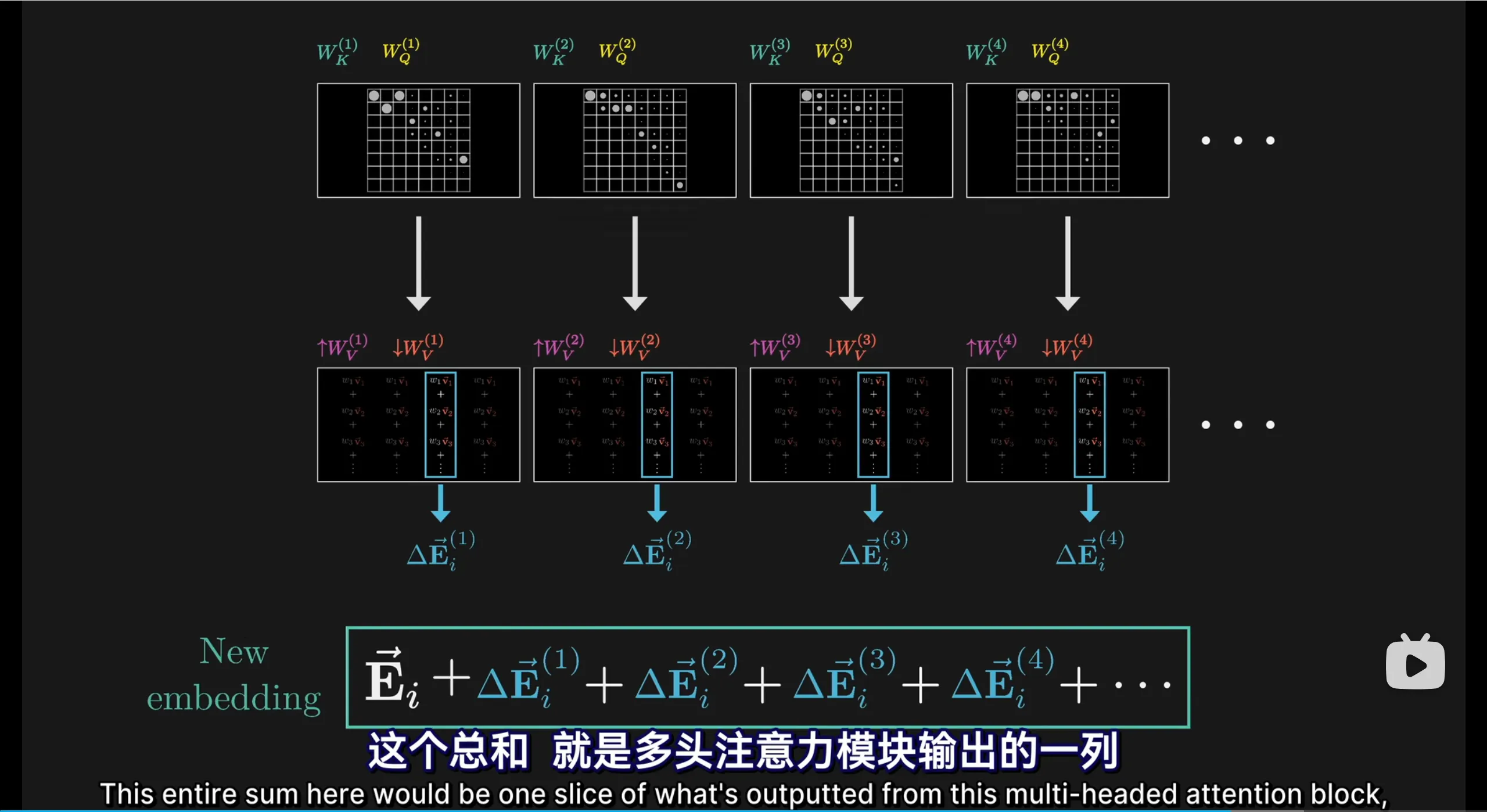
理论上,value向量最后要与token向量相加,所以是同维的,比key/query维数大很多,那么\(W_V\)的维数也会很大。实际上,\(W_V\)矩阵的维数会与\(W_k\)和\(W_Q\)维数之和相等,这对并行运行多个注意力头尤其重要
所以\(W_V\)会被低秩分解为两个矩阵相乘,\(W_V = W_{V\,up} \times W_{V\,down}\)(视频里的称呼),实际上所有的\(W_{V\,up}\)矩阵会合作一个output矩阵
这个过程会重复很多次,因为有很多种不同的上下文更新模式,尽管模型的具体行为是难以解释的
基于多头注意力模式multi-headed attention,同一层注意力模块里,会有多个值-查询操作,当然最后注意力模块依旧会有很多层
另外,训练时同一份预料的各个子序列都会用于训练,比如
我
我是
我是谁…
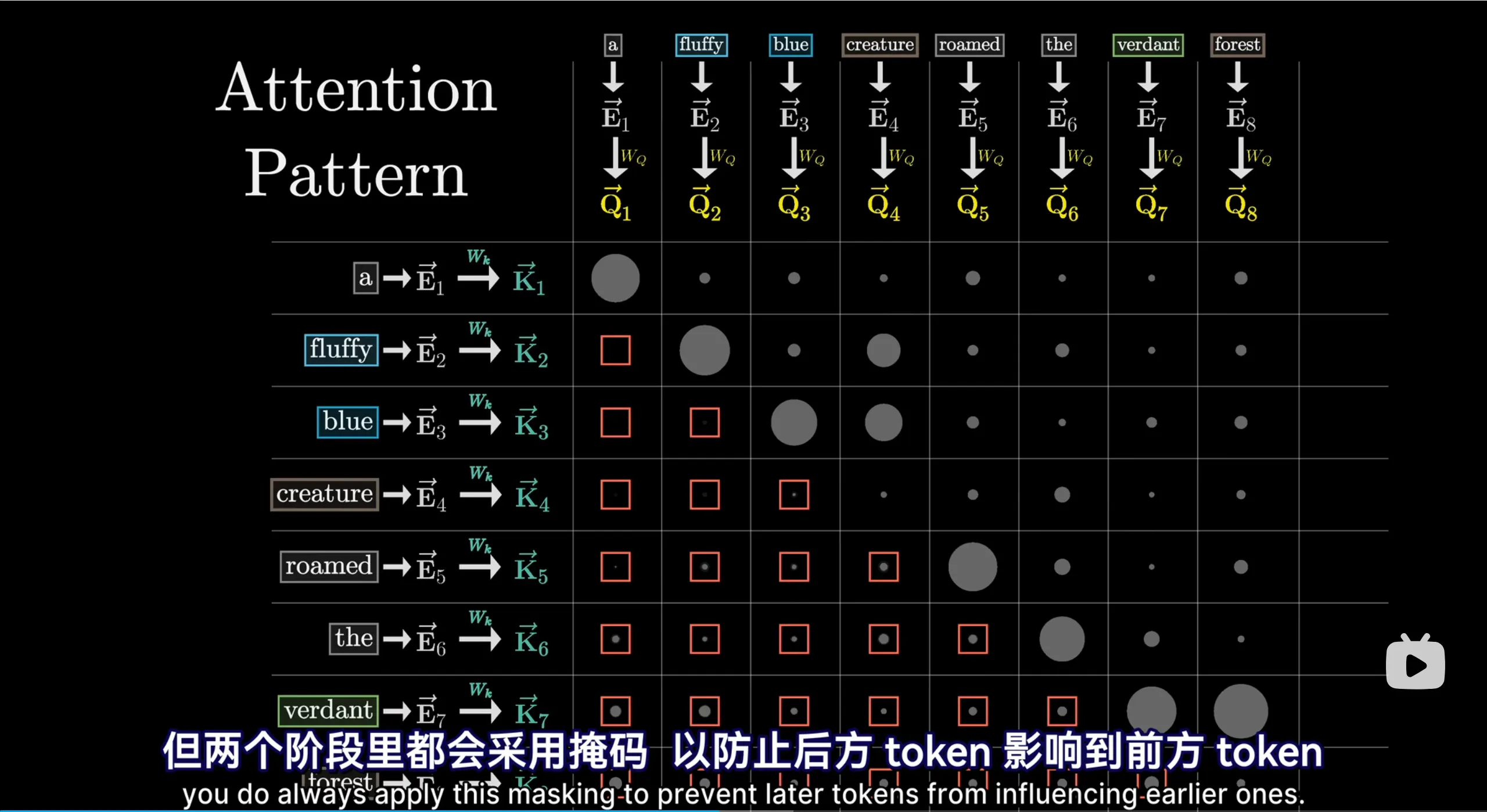
这就要求注意力模块里,后方的token不影响前面的,需要引入掩码 mask机制
把对角线之下的点积设为\(-\infty\) 然后再softmax
实际上GPT训练之后也运用了掩码机制,在上面的value阶段,也看得出来这些点积都为0
最开始说这是自注意力机制,还有针对两类数据进行的交叉注意力机制cross-attention,用于文本翻译、语音转文字等
和自注意力机制的区别是,查询矩阵和键矩阵来自不同的训练数据。文本翻译中,可能一个来自英文,一个来自中文,就能反映一种语言中的哪些词对应另一种语言中的哪些词
而且也用不着掩码
在原论文中,被写作这个公式:
\[\text{Attention}(Q,K,V) = \text{softmax}(\frac{QK^T}{\sqrt{d_k}})V\]其中\(\sqrt{d_k}\)是key-query空间维数的平方根,为了保证稳定性
这里的Q和K是所有query/key作为行向量组成的矩阵,转置相乘后逐行softmax,得到的矩阵