最基本的神经网络——多层感知器MLP(MultiLayer Perceptron) 概说
输入部分有24×24共576个像素,抽象成576个神经元/节点,神经元的有0-1的值代表像素灰度。这就是MLP的第一层
输出部分有10个神经元,代表十个数字的激发强度/概率
中间有两个隐含层,具体的细节之后解释
一层神经元的特定激活情况叫做图案/模式(模式识别) Pattern
每一个神经元的值都由上一层所有神经元的值、神经元之间的连线的权重 weight ,和一个偏差 bias 决定
神经元可以看作一个函数,自变量为上一层的所有神经元,参数是权重和偏差,因变量是自己的值
为了保证神经元的值还是在0-1之间,结果要带入一个 \(R\to[0,1]\) 的压缩函数
(注意目标和GPT章节3B1B 嵌入和解嵌入所用的softmax不同,这里不需要所有值的和为1)
这里使用sigmoid函数 \(\sigma(x) = \frac{1}{1+e^{-x}}\)
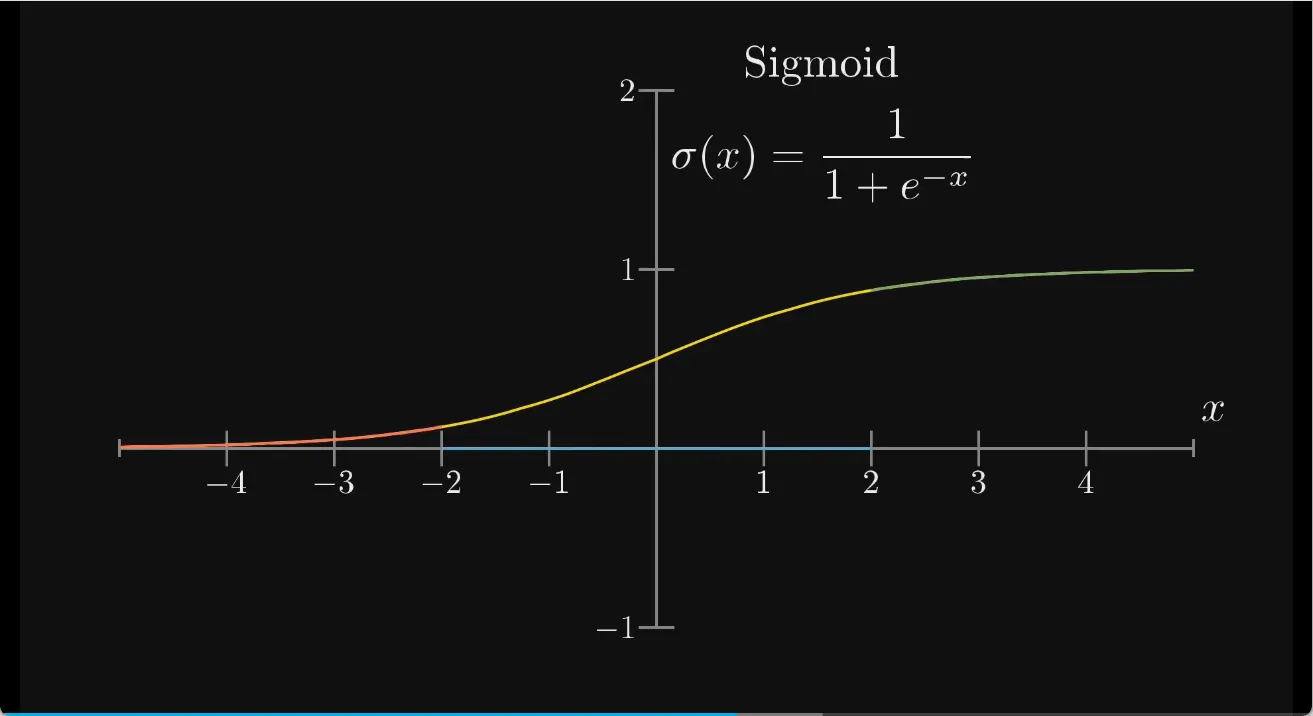
但是实际上,常用线性整流函数 \(\text{ReLU}(x) = \max(0,x)\),更好训练,效果也不会差。可能是为了模拟生物神经元的激发阈值,不超过某个值就不激发
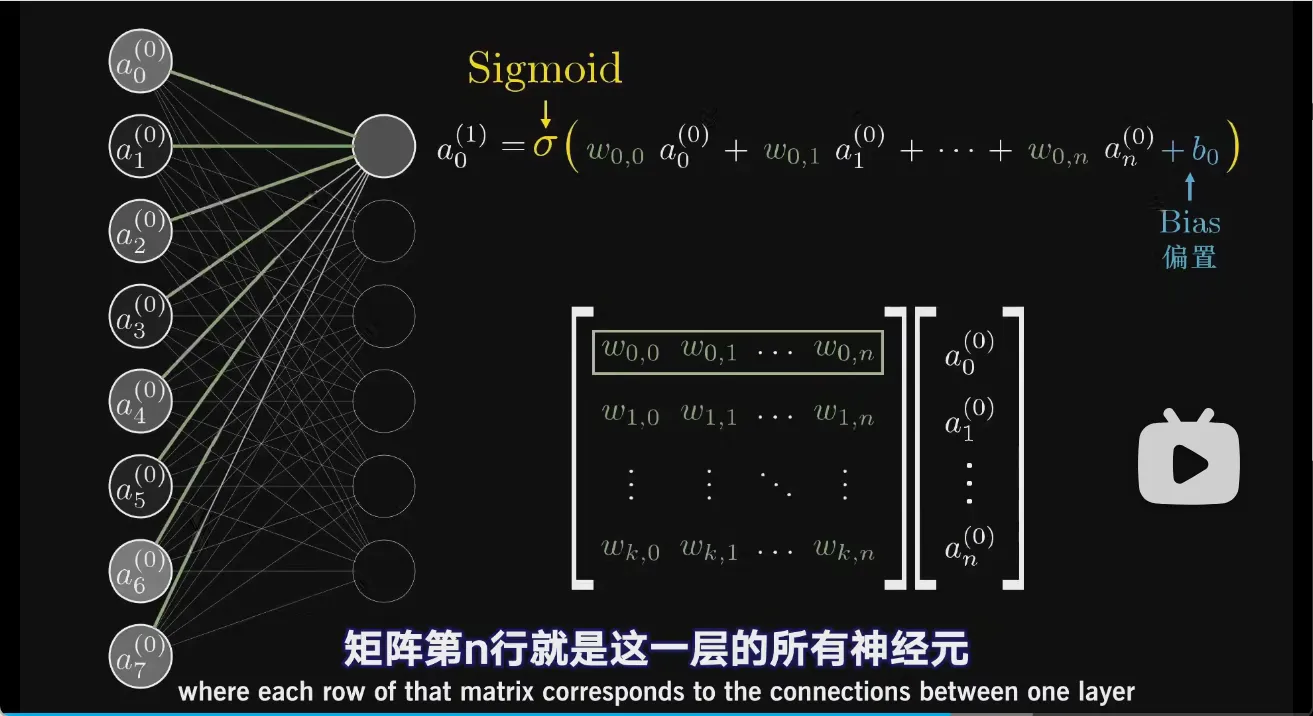
\[a^{(1)}_{0} = \sigma(w_{0,0}a^{(0)}_{0}+w_{0,1}a^{(0)}_{1}+\cdots+w_{0,n}a^{(0)}_{n}+b_0)\]这里 \(a^{(1)}_{0}\) 的上标下标代表第1层的第0个神经元。\(w_{0,0}\) 的第一个0代表与下层第0个神经元连线,第二个0代表与上一层的第0个神经元连线。
这是对某一个神经元的写法,对于一整层,写成矩阵乘法的形式
\[\begin{pmatrix} w_{0,0} & w_{0,1} & \cdots & w_{0,n} \\ w_{1,0} & w_{1,1} & \cdots & w_{1,n} \\ \vdots & \vdots & \ddots & \vdots \\ w_{k,0} & w_{k,1} & \cdots & w_{k,n} \end{pmatrix} \begin{pmatrix} a^{(0)}_{0} \\ a^{(0)}_{1} \\ \vdots \\ a^{(0)}_{n} \end{pmatrix} + \begin{pmatrix} b_0 \\ b_1 \\ \cdots \\ b_k \end{pmatrix} \xrightarrow{\sigma(x)} \begin{pmatrix} a^{(1)}_{0} \\ a^{(1)}_{1} \\ \vdots \\ a^{(1)}_{k} \end{pmatrix}\]或
\[\vec{a}^{(1)} = \sigma(\mathbf{W}\vec{a}^{(0)}+\vec{b})\]左边矩阵的每一行都代表右侧输出神经元的所有权重,整个矩阵代表第0层的权重
第0层有n个神经元,而第1层有k个

整个网络就是一个函数,自变量是图像的784个像素灰度值,输出10个数字的概率值,参数为极大量的权重和偏差
机器学习实际上就是通过训练数据和某种算法,让机器自己调整这些所有的参数,从而使代价函数最小化