简化梯度下降法计算量的方法:
- 不对所有训练样本进行整体计算,而是随机分类成 minibatch 再抽样,对每一个抽样的结果进行梯度下降 也成为随机梯度下降SGD stochastic gradient descent (在1000个数据点下,这东西提升了我线性回归小项目将近10倍效率)
- cost函数不采用平均 (或者说,在我的线性回归练手里,求偏导的不是total_cost函数而是single_cost函数,得到所有单个样本需要的梯度之后再做平均)
对于单个样本来说,假设想要识别数字2,那么在最后的10个神经元中,数字2代表的神经元的值就要增大,这里一共有三条路径:
- 增大和数字2神经元相关的权重 weight
- 调整上一层神经元的值(根据权重正负)
- 增大偏差 bias
对于路径1的增大权重,应当优先增加连接的神经元值较大的权重,因为权重和上一层神经元是相乘的; 同理对于路径2,也应当调整权重较大的神经元。虽然不能直接调整神经元的值,只能以此类推的调整上上层的权重和偏差
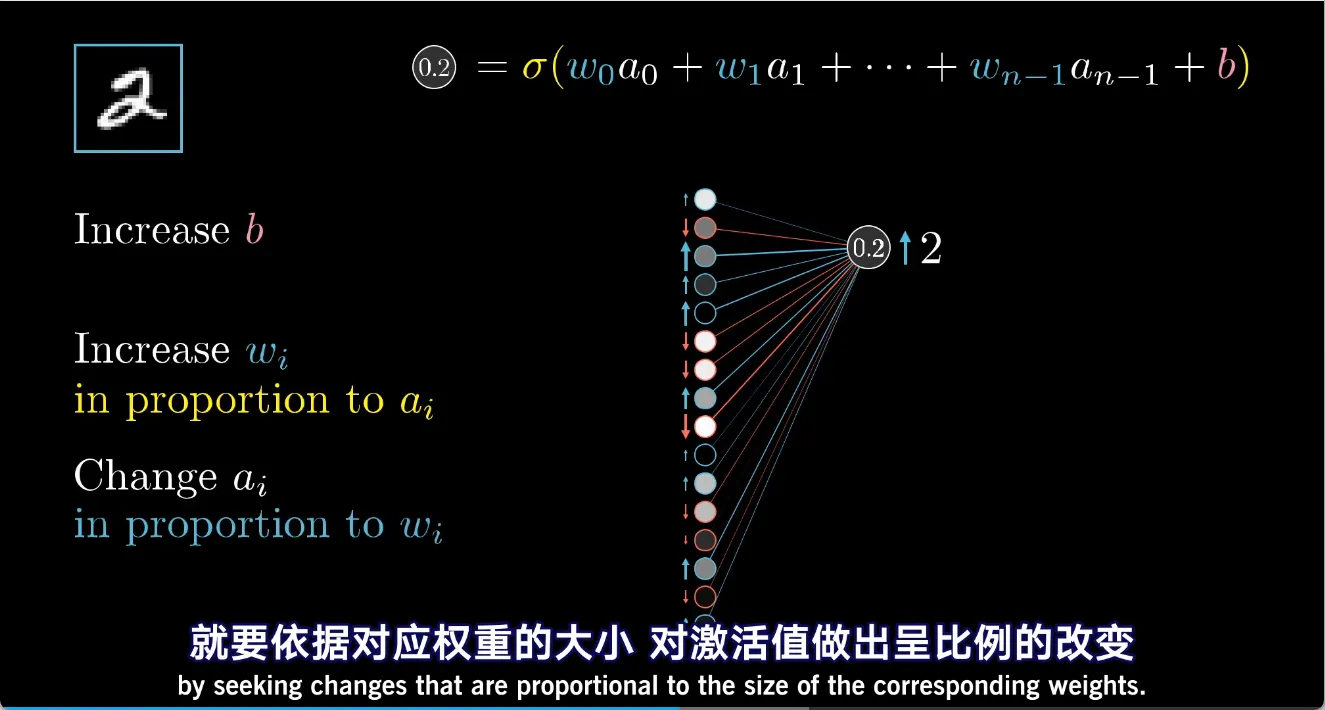
此外,数字2的神经元值要增大,其他数字的值就要减小。把所有10个数字神经元需要的变化累加到上一层,又是以此类推
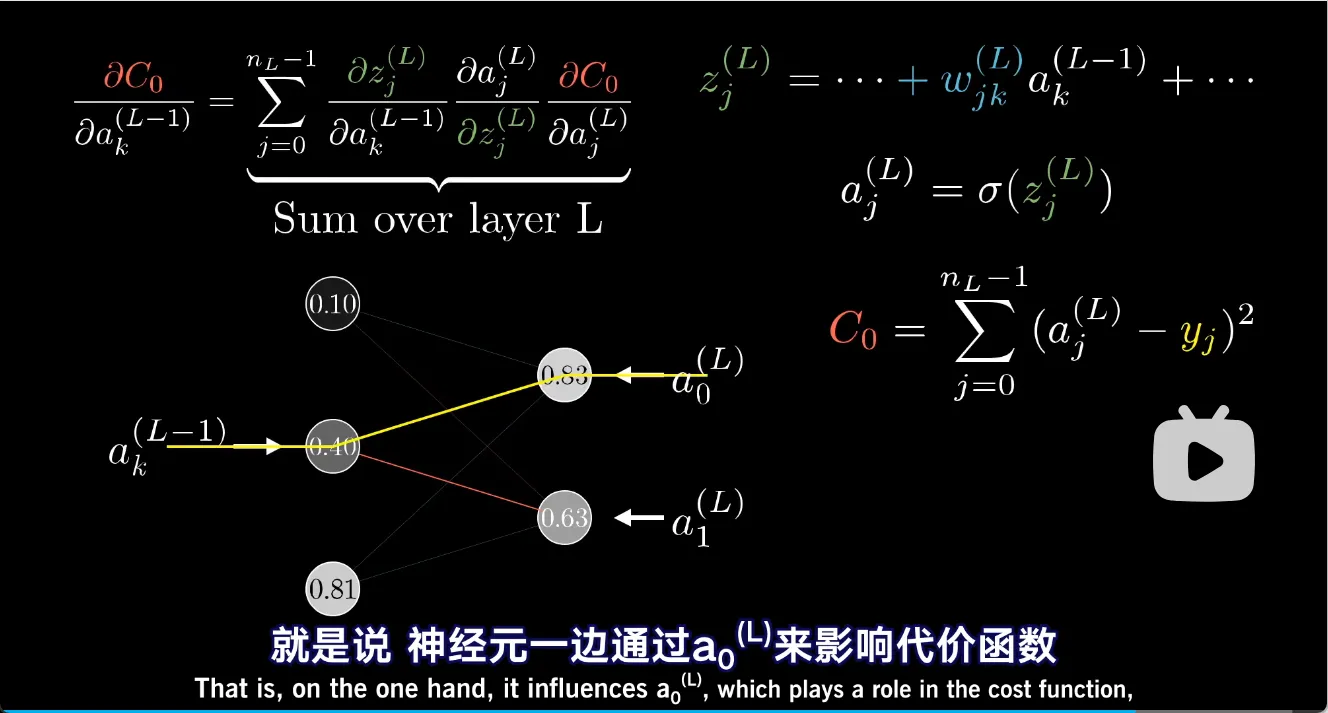
下面是形式化的表述,为了方便起见,以一个链状的神经网络为例:
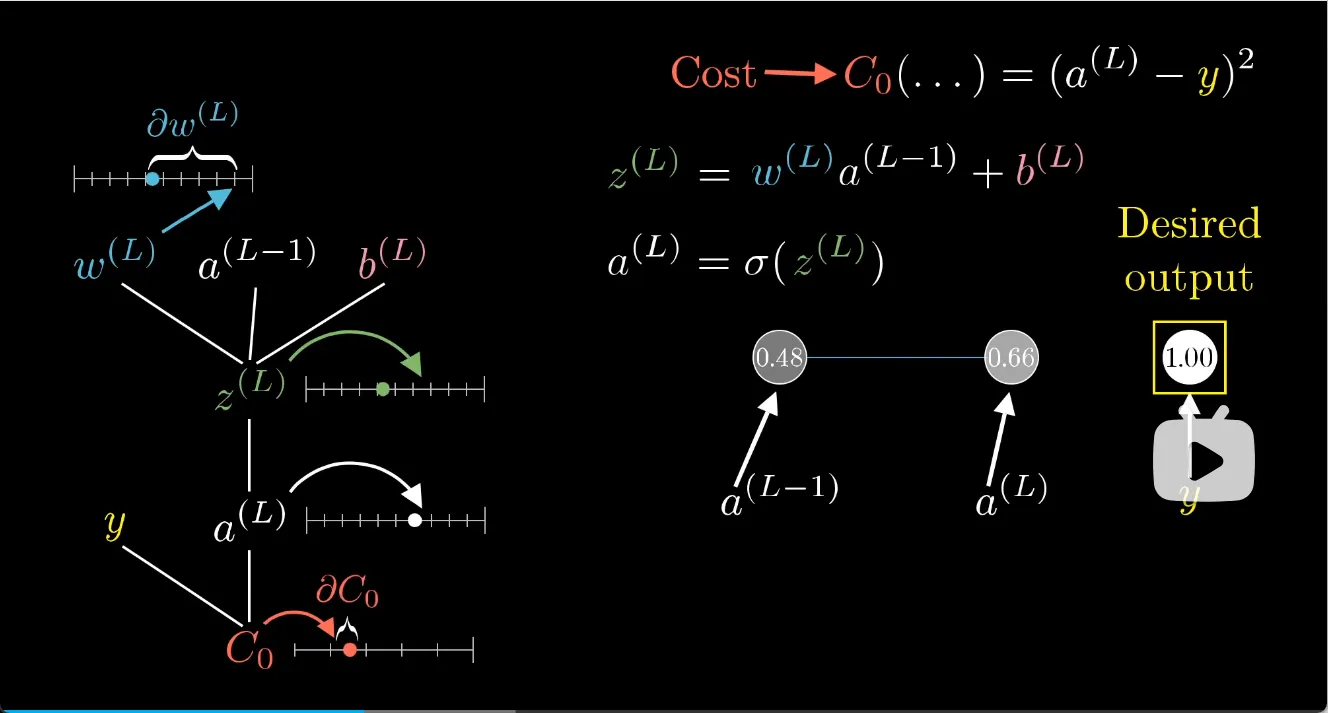
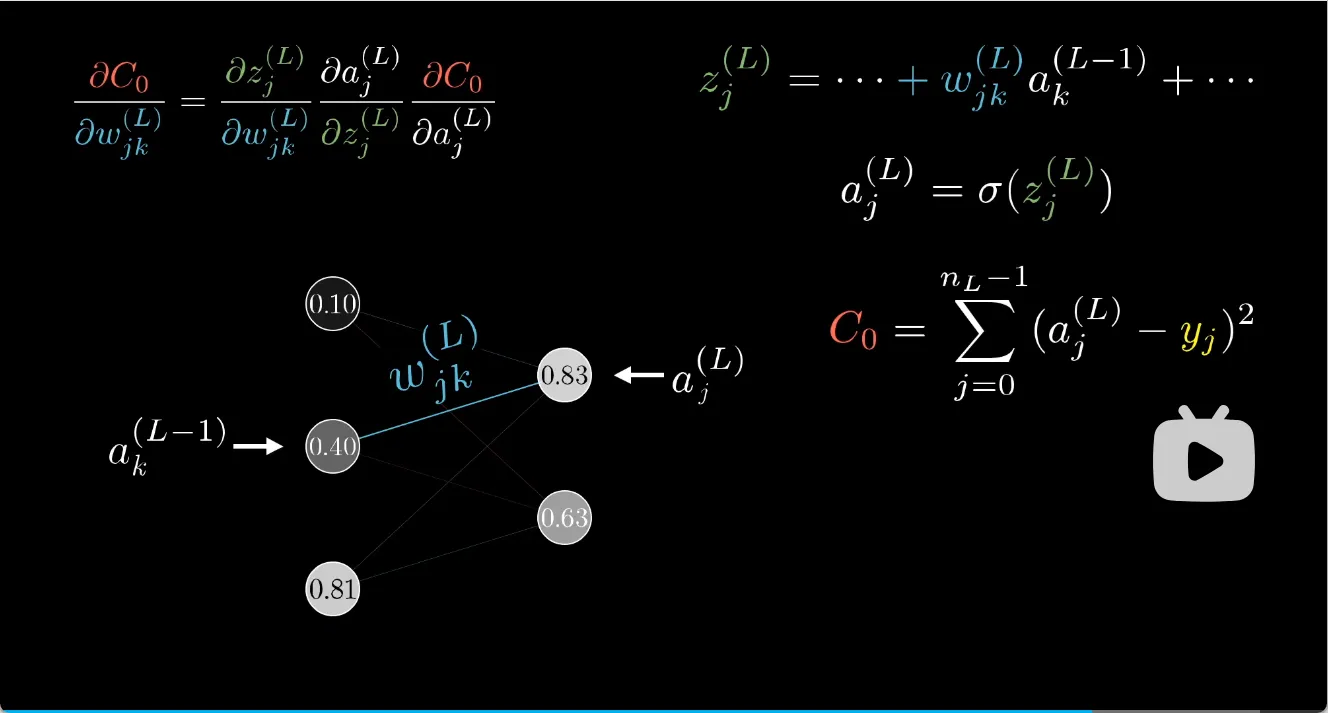
比如求一个样本的代价\(C_0\)对\(w^{(L)}\)的偏导
\[\frac{\partial{C_0}}{\partial{w^{(L)}}} = \frac{\partial{C_0}}{\partial{a^{(L)}}} \frac{\partial{a^{(L)}}}{\partial{z^{(L)}}} \frac{\partial{z^{(L)}}}{\partial{w^{(L)}}} = 2(a^{(L)}-y) \ \sigma'(z^{(L)}) \ a^{(L-1)}\]其实就是导数的链式法则
如果对\(a^{(L)}\)求偏导,结果要不断对上一层计算
然而实际上,总的代价函数对一个变量(这里是\(w^{(L)}\))的偏导是所有单个样本的偏导平均值
\[\frac{\partial{C}}{\partial{w^{(L)}}} = \sum_{i=0}^{n-1} \frac{\partial{C_i}}{\partial{w^{(L)}}}\]这仅仅是梯度向量对某个变量的一个分量,完整的梯度包含所有变量
一个更一般的例子也类似,只不过\(C_0\)包含多个结果和预期的平方差之和,\(z^{(L)}\)来自于多个上层神经元
不过链式法则里,\(C_0\)对于\(a^{(L)}_k\)的偏导发生了变化,因为\(a^{(L)}_k\)可以对多个结果神经元产生影响